
Focusing on image-text alignment, we introduce SeeTRUE, a comprehensive benchmark, and two effective methods: a zero-shot VQA-based approach and a synthetically-trained, fine-tuned model, both enhancing alignment tasks and text-to-image reordering.
🤗
Test Dataset📄
Train Dataset🖼
Train Images
Focusing on image-text alignment, we introduce SeeTRUE, a comprehensive benchmark, and two effective methods: a zero-shot VQA-based approach and a synthetically-trained, fine-tuned model, both enhancing alignment tasks and text-to-image reordering.
Automatically determining whether a text and a corresponding image are semantically aligned is a significant challenge for vision-language models, with applications in generative text-to-image and image-to-text tasks. In this work, we study methods for automatic text-image alignment evaluation. We first introduce SeeTRUE: a comprehensive evaluation set, spanning multiple datasets from both text-to-image and image-to-text generation tasks, with human judgements for whether a given text-image pair is semantically aligned. We then describe two automatic methods to determine alignment: the first involving a pipeline based on question generation and visual question answering models, and the second employing an end-to-end classification approach by finetuning multimodal pretrained models. Both methods surpass prior approaches in various text-image alignment tasks, with significant improvements in challenging cases that involve complex composition or unnatural images. Finally, we demonstrate how our approaches can localize specific misalignments between an image and a given text, and how they can be used to automatically re-rank candidates in text-to-image generation.
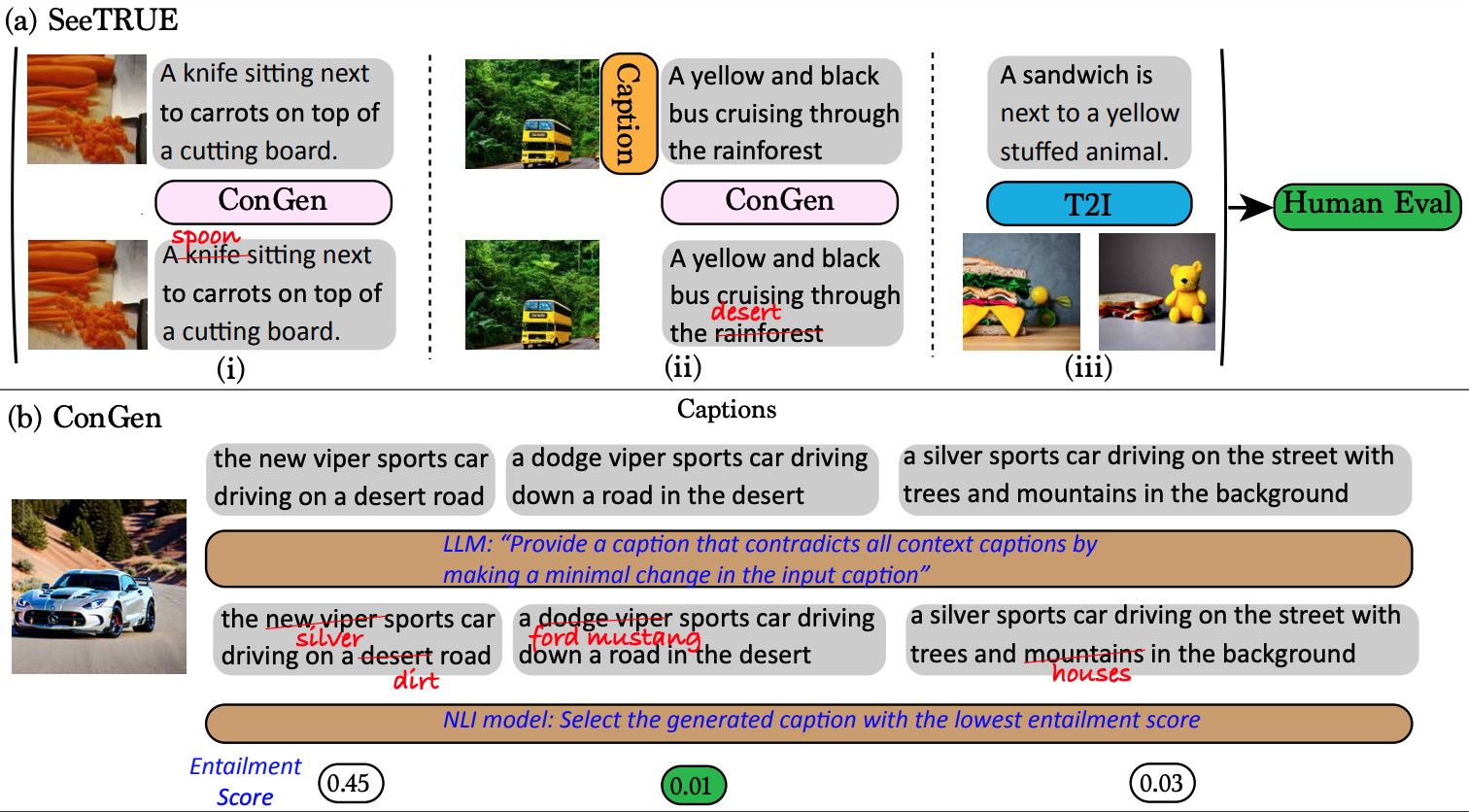
A comprehensive benchmark constructed using text-to-image (t2i) and image-to-text (i2t) models, LLMs, and NLI, including a mix of natural and synthetic images, captions, and prompts.
A novel approach that utilizes question generation and visual question answering to create questions related to the text, ensuring the correct answer is obtained when asking these questions with the provided image.

Our methods surpass prior approaches in various text-image alignment tasks, with significant improvements in challenging cases involving complex composition or considering generated images.
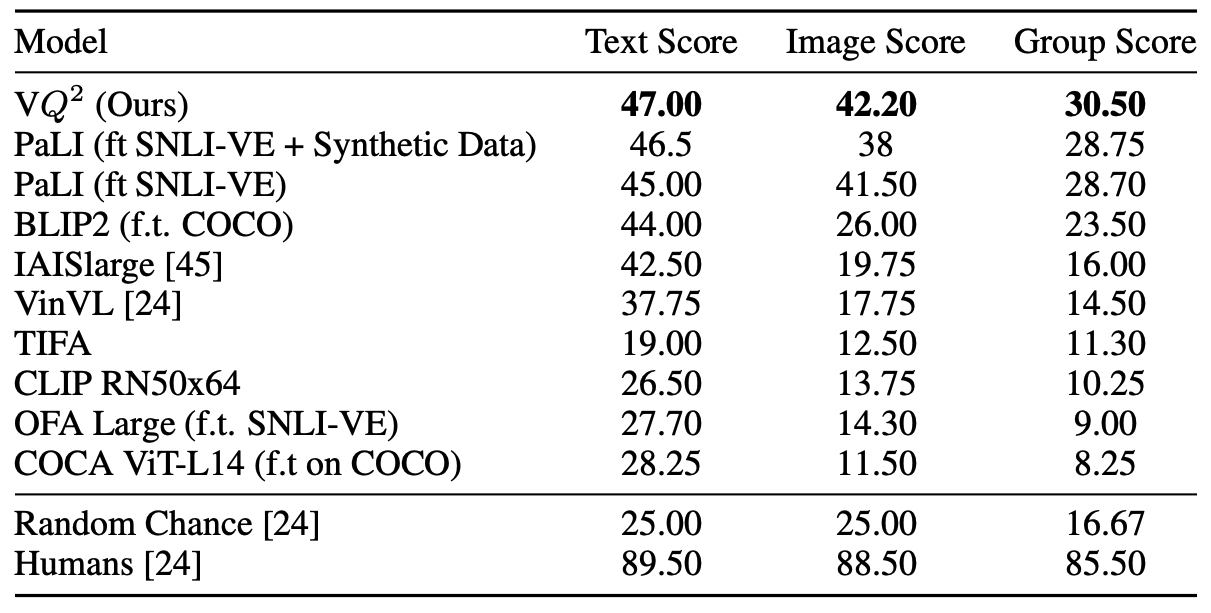
We achieve state-of-the-art results on the challenging Winoground dataset, which requires strong visual reasoning and compositionality skills.
Our methods effectively handle contradicting captions and question/answer pairs with lower VQ^2 alignment scores, revealing the contradiction reason.

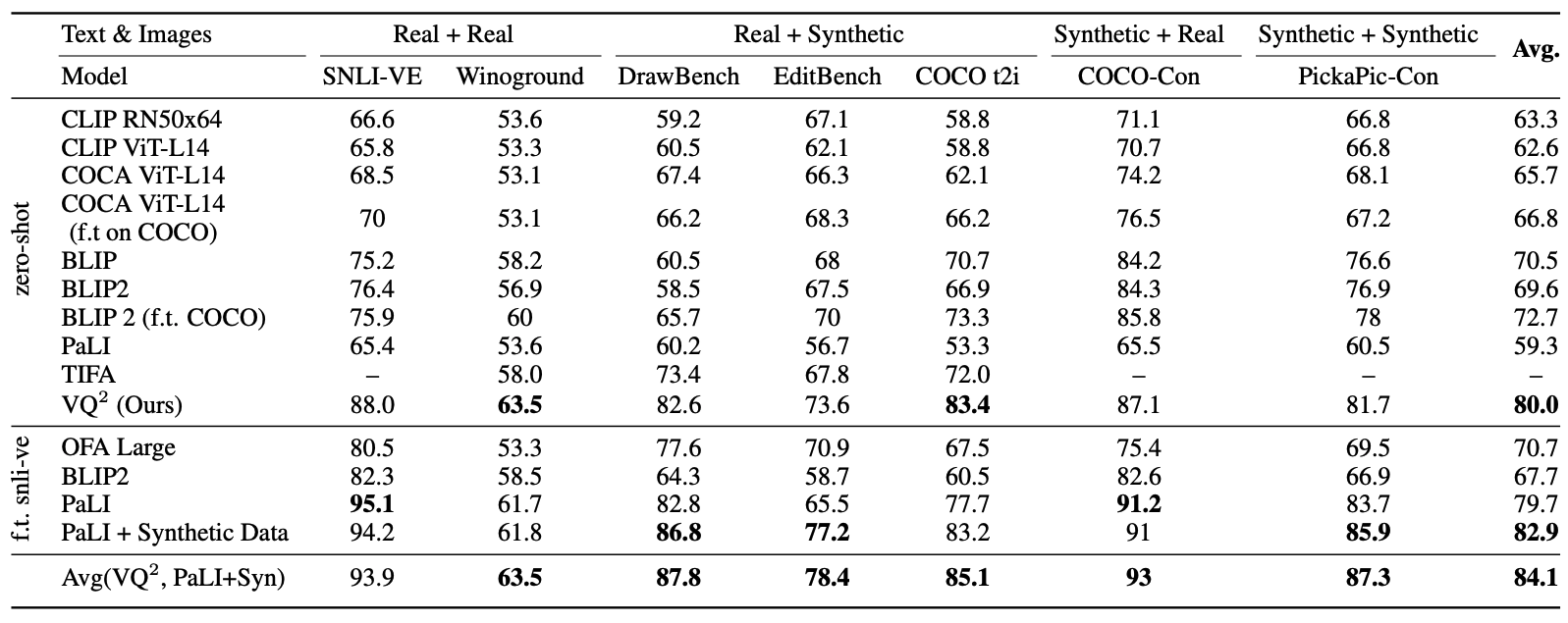
Our VQ^2 and PaLI scores are highly correlated with human ranking in evaluating text-to-image models. It also offers a way to evaluate dataset difficulty, revealing DrawBench as a harder dataset compared to COCO-t2i.
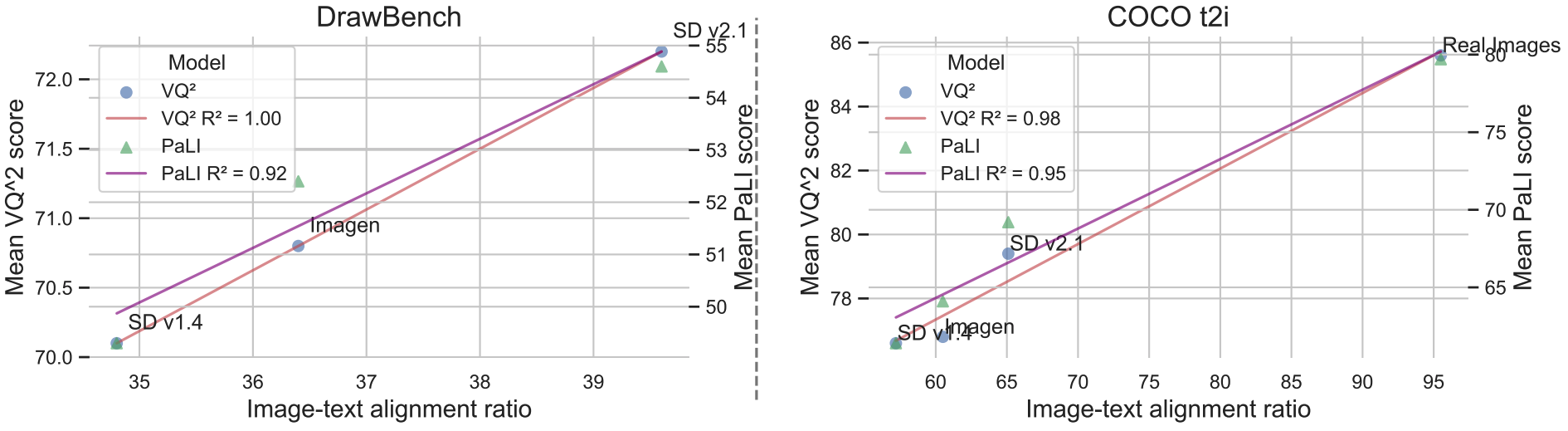
VQ^2 and PaLI consistently achieves higher quality scores compared to CLIP when reranking image candidates in the DrawBench and COCO-t2i datasets, showcasing its potential in enhancing text-to-image systems.

@article{yarom2023you,
title={What You See is What You Read? Improving Text-Image Alignment Evaluation},
author={Yarom, Michal and Bitton, Yonatan and Changpinyo, Soravit and Aharoni, Roee and Herzig, Jonathan and Lang, Oran and Ofek, Eran and Szpektor, Idan},
journal={arXiv preprint arXiv:2305.10400},
year={2023}
}